Функция np.genfromtxt() в Python — это функция из NumPy. Эта функция широко используется для чтения данных из текстовых файлов, особенно когда данные имеют табличный формат со строками и столбцами.
- Синтаксис
- Параметры
- В возвращаемых значениях
- 1. genfromtxt работает с файлом, разделенным запятыми, со смешанным типом dtype
- 2. С использованием dtype = None
- 3. С указанным типом dtype и именами
- 4. Со столбцами фиксированной ширины
- 5. Для отображения комментариев
Синтаксис
Основной синтаксис функции np.genfromtxt() в Python следующий:
numpy.genfromtxt(fname, dtype=float, comments='#', delimiter=None, skip_header=0, skip_footer=0, converters=None, missing_values=None, filling_values=None, usecols=None, names=None, excludelist=None, deletechars=None, replace_space='_', autostrip=False, case_sensitive=True, defaultfmt='f%i', unpack=False, usemask=False, loose=True, invalid_raise=True, max_rows=None, encoding='bytes')
Параметры
Функция np.genfromtxt() в Python имеет несколько параметров, каждый из которых позволяет нам указать, как следует читать и интерпретировать наши данные.
Здесь:
- fname: имя файла или файловоподобный объект для чтения. Это может быть строка или pathlib. Объект пути или генератор.
- dtype: тип данных результирующего массива. Если None, типы dtypes будут определяться содержимым каждого столбца индивидуально.
- comments: символ, используемый для обозначения начала комментария.
- separator: строка, используемая для разделения значений. По умолчанию любые пробелы действуют как разделитель.
- skip_header: количество строк, которые нужно пропустить в начале файла.
- skip_footer: количество строк, которые нужно пропустить в конце файла.
- converters: номер столбца словаря, отображающий функцию, которая преобразует этот столбец в число с плавающей запятой.
- Missing_values: набор строк, соответствующих отсутствующим данным.
- fill_values: набор значений, которые будут использоваться по умолчанию при отсутствии данных.
- usecols: какие столбцы читать, где 0 — первый.
- names: если True, первая строка файла читается как имена столбцов.
- list of exceptions: список имен, которые необходимо исключить. Этот список добавляется к списку по умолчанию [‘return’, ‘file’, ‘print’].
- deletechars: строка, содержащая недопустимые символы, которые необходимо удалить из имен.
- replace_space: символ, используемый для замены пробелов в именах переменных.
- autostrip: следует ли автоматически удалять пробелы из переменных.
- Case_sensitivity: если установлено значение True, имена полей будут чувствительны к регистру.
- defaultfmt: формат, используемый для определения имен полей по умолчанию.
- unpack: Если True, возвращаемый массив транспонируется.
- usemask: если True, вернуть замаскированный массив.
- free: если значение равно False, возникает ошибка при обнаружении недопустимой строки.
- valid_raise: если значение равно False, пропускать недопустимые строки.
- max_rows: максимальное количество строк для чтения.
- encoding: кодировка входного файла.
В возвращаемых значениях
Функция np.genfromtxt() в Python возвращает массив, по умолчанию это массив NumPy. Если usemask имеет значение True, возвращается маскированный массив. Этот массив будет иметь форму и тип данных, указанные входными параметрами и содержимым файла.
Давайте рассмотрим некоторые варианты использования функции np.genfromtxt() в Python:
1. genfromtxt работает с файлом, разделенным запятыми, со смешанным типом dtype
Чтобы прочитать файл, содержащий столбцы с разными типами данных (например, целые числа, числа с плавающей запятой, строки), и позволить NumPy автоматически определять соответствующий тип данных для каждого столбца. Мы можем использовать функцию np.genfromtxt() в Python.
import numpy as np
data = np.genfromtxt('C:/Users/kumar/OneDrive/Desktop/Book1.csv', delimiter=',', dtype=None, names=True, encoding='utf-8')
print(data)
Выход:
[(1, 'Jade', 40000.12)(2, 'David', 35000.25)(3, 'Alex', 42000.35) (4, 'Betty', 38000.18)(5, 'Zoe', 45000.24)]
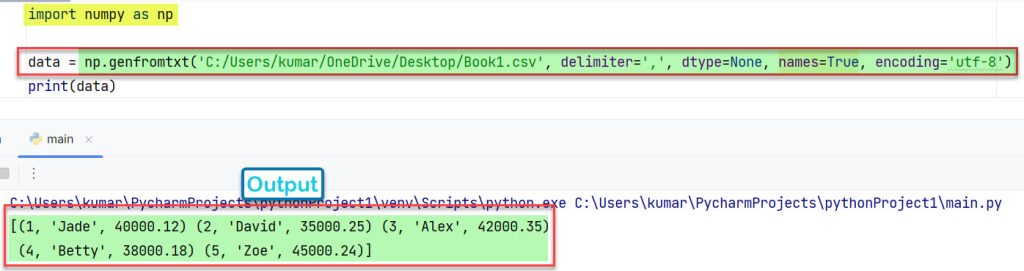

2. С использованием dtype = None
NumPy автоматически определяет и назначает типы данных для каждого столбца в наборе данных, что особенно полезно, когда конкретные типы данных столбцов заранее не известны.
Например:
import numpy as np
data = np.genfromtxt('C:/Users/kumar/OneDrive/Desktop/Book1.csv', delimiter=',', dtype=None)
print(data)
Выход:
[(b'\xef\xbb\xbf0', 11111, 45000)(b'1', 16041, 40000) (b'2', 16043, 35000)(b'3', 16029, 42000)(b'4', 16061, 38000) (b'5', 16039, 45000)]
Ниже показано изображение, отображающее результаты выполнения кода в среде PyCharm.

3. С указанным типом dtype и именами
Определение типов данных и имен столбцов для считываемого набора данных. Он обеспечивает контроль над интерпретацией каждого столбца в файле данных, гарантируя, что каждый столбец обрабатывается с использованием предполагаемого типа данных и идентифицируется определенным именем.
Например:
import numpy as np
dtype = [('id', int),('name', 'U10'),('value', float)]
names = ['ID', 'Name', 'Value']
data = np.genfromtxt('C:/Users/kumar/OneDrive/Desktop/Book1.csv', delimiter=',', dtype=dtype, names=names, skip_header=1)
print(data)
Выход:
[(1, 'Jade', 40000.12)(2, 'David', 35000.25)(3, 'Alex', 42000.35) (4, 'Betty', 38000.18)(5, 'Zoe', 45000.24)]
После выполнения кода в Pycharm результат можно увидеть на снимке экрана ниже.
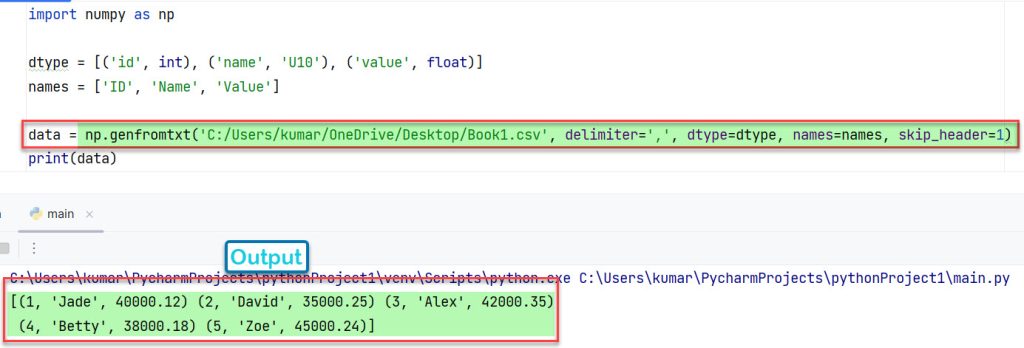

4. Со столбцами фиксированной ширины
Данные считываются из файла, где столбцы определяются шириной в символах, а не разделителем. Это особенно полезно для анализа данных, отформатированных в столбцах с фиксированной шириной символов.
Например:
import numpy as np
data = np.genfromtxt('C:/Users/kumar/OneDrive/Desktop/Book1.csv', delimiter=[4, 9, 5], dtype=None, names=['ID', 'Name', 'Score'], encoding='utf-8')
print(data)
Выход:
[('\ufeffID,', 'Name Code', ',Sala')('1,Ja', 'de,40000.', '12\n')
('2,Da', 'vid,35000', '.25\n')('3,Al', 'ex,42000.', '35\n')
('4,Be', 'tty,38000', '.18\n')('5,Zo', 'e,45000.2', '4\n')]
На следующем изображении показаны результаты, полученные в результате выполнения кода в PyCharm.

5. Для отображения комментариев
Эта концепция заключается в игнорировании строк комментариев (обычно аннотаций или описаний) в файле данных. Он предполагает указание символа комментария, чтобы строки, начинающиеся с этого символа, не обрабатывались как данные.
Например:
import numpy as np
data = np.genfromtxt('test.txt', delimiter=[4, 9, 5], dtype=None, comments='#', encoding='utf-8')
print(data)
Выход:
[['1,5.' '2,Python\n' 'False'] ['2,3.' '5,Guides' 'False']]
Результат запуска кода в PyCharm визуально представлен на снимке экрана ниже.

